NumPyを使ってCERN ROOTの解析用ダミーデータを生成する2-物理実験っぽいデータの生成編
やること
解析用のダミーデータの生成。
研究室の教育用に。
コード
import numpy as np kNumEvent = 10000 fout = open("output.dat","w") for i in range(kNumEvent): rand1 = round(np.random.normal(0, 1),5) # 正規分布(平均, 標準偏差) rand2= round(np.random.rand(),5) # 一様分布() rand3 = round(np.random.binomial(100,0.3),5) # 二項分布(試行回数, 成功確率) rand4 = round(np.random.beta(2,5),5) # β分布(α値, β値) rand5 = round(np.random.gamma(4,1),5) #γ分布(形状母数(k), 尺度母数(Θ)) rand6 = round(np.random.chisquare(3),5) # χ二乗分布(自由度(k)) rand7 = np.random.normal(1000, 10) rand8 = np.random.normal(1300, 2) def func1(X,a,b,c): Y = a*X**(-0.5) + b/X + c return Y tmp_ADC = round(rand5*200) tmp_TDC1 = round(func1(rand5*200,1000,100,rand1*10+rand2*5+rand7)) tmp_TDC2 = round(rand7+rand8) tmp_TDC3 = round(1000+rand2*5) fout.write(str(i)+" "+str(tmp_ADC)+" "+str(tmp_TDC1)+" "+str(tmp_TDC2)+" "+str(tmp_TDC3)+" "+ str(rand1)+" "+str(rand2)+" "+str(rand3)+" "+str(rand4)+" "+str(rand5)+" "+str(rand6)+"\n") fout.close() print("F!!!!!")
結果

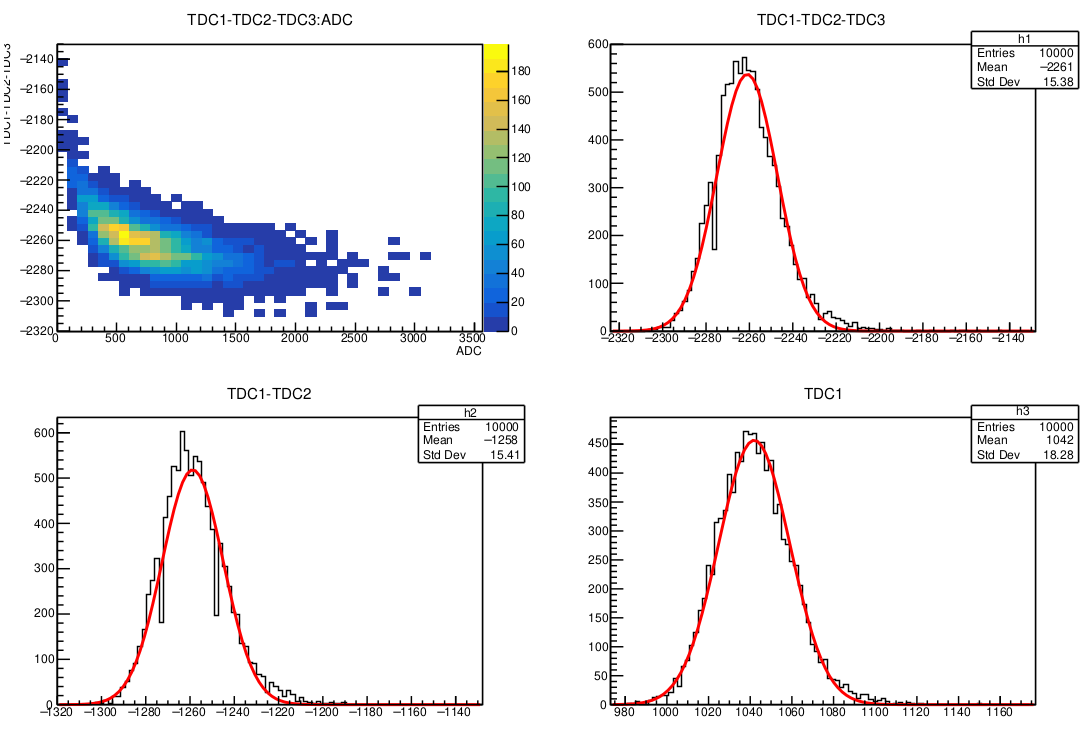
NumPyを使ってCERN ROOTの解析用ダミーデータを生成する1-ランダムデータ編
やること
ダミーのテキストデータをNumPyで作る。
色々な形状な分布を生成して後々ROOTで解析する。
コード
import numpy as np kNumEvent = 1000 fout = open("output.dat","w") for i in range(kNumEvent): rand1 = round(np.random.normal(0, 1),5) # 正規分布(平均, 標準偏差) rand2= round(np.random.rand(),5) # 一様分布() rand3 = round(np.random.binomial(100,0.3),5) # 二項分布(試行回数, 成功確率) rand4 = round(np.random.beta(2,5),5) # β分布(α値, β値) rand5 = round(np.random.gamma(5,1),5) #γ分布(形状母数(k), 尺度母数(Θ)) rand6 = round(np.random.chisquare(3),5) # χ二乗分布(自由度(k)) fout.write(str(rand1)+" "+str(rand2)+" "+str(rand3)+" "+str(rand4)+" "+str(rand5)+" "+str(rand6)+"\n") fout.close() print("F!!!!!")
WindowsユーザーがCERN ROOT 6をいい感じにコーディングできるようになるまで3-ROOTのinstall編
今回やること
・ROOT 6のinstall
・PyROOT(Pythonで動かすroot)の設定
方法
ROOT 6のinstall
ROOTは色々なインストール方法がある。
ROOT公式によるとCentOS 8ではyumからROOTをインストールするのが最も楽。
root.cern
ということでterminalを起動して以下のコマンドを打ち込む
$ su
これで管理者権限を得られる。
この状態で
# yum install epel-release # yum install root
これでROOTをインストールできる。
ここで一度再起動する。
# reboot
ROOTがインストールできているか確認する。
$ root
以下の画面が表示されればおk。

PyROOTのinstall
PyROOTはPython内でROOTを扱うためのPython moduleである。
便利なmoduleなので入れておくとよいだろう。
次回以降に利点を紹介する。
ROOT公式の説明では「ROOT内にあるROOT.pyをPythonのPATHに追加しろ」と書いてある。
yumでインストールした場合、ROOT.pyが見つからない。
そこで再びyumからPyROOTをインストールする。
$ su # yum install python3-root # reboot
これで他に何もしなくともPyROOTをインストールできる。
PyROOTが使えるかどうかPythonを起動して確認する。
$ python3 >>> import ROOT >>>
これで何も表示されなければおk。
次回
ROOTの基本を紹介する。
WindowsユーザーがCERN ROOT 6をいい感じにコーディングできるようになるまで2-CentOS8・VMwareの設定編
方法
キーボードを日本語化
<基本>terminal
基本的にはこの「terminal」に文字を入力することでPC(CentOS)を操作する。


開くとこんな感じ。以下、この記事ではこの「terminal」上に書くコマンドを以下のように記述する。
$ ここにコマンドを入力して操作
詳しいコマンド等は自分で検索されたし。
一般日本人がよく使うキーボードは「日本語配列」と呼ばれる配列である。
これは日本語版のOSではデフォルトで設定されているが、英語版のOSでは「US配列」が主流である。
キーボードそのものの見分け方は簡単で、「Enter」を見れば一発で分かる。
日本語配列のキーボードは以下のような形をしている。
www.amazon.co.jp
OS上で見分ける方法も簡単で「Shift」+「2」を押して「"」が出れば日本語配列、「@」が出ればUS配列である。
<本題>キーボードの日本語化
始めに、キーボードの設定に「Japanese」を追加する。




US配列を消去して完了。






余談①
実はCentOS8を日本語表記にすることはできる。
メリット
・terminalの警告文やエラー文がちょっとわかりやすくなる(かなりうれしい)
デメリット
・「Desktop」が「デスクトップ」になり、tarminal上で操作しにくくくなる(ここだけ英語表記にはできる)
・エラー文が日本語だと単純なエラー以外は記事が見つからなくなる(詳しい人はみんな英語でやってるらしい)
このため筆者的には非推奨
余談②
・emacsは起動したときに別windowで開くもの(GUI版)とterminal上で開くものがある。
GUI版の方が初心者にはおすすめ。
・emacsはコーディング含むテキストを編集できるソフトだが、windowsのショートカットキーは全く通用しない。
各自覚えるべし。
次回
ROOT 6のinstallと、PyROOTのコーディングのための設定を行う。
WindowsユーザーがCERN ROOT 6をいい感じにコーディングできるようになるまで1-対応OS導入編
はじめに
筆者は何者か
筆者は修士課程で実験物理学を学んでいた物理オタク。
何でこんな記事書いた
rootは筆者のようなバカ大学生が理解するにはちょっと難しいし、日本語で優しく教えてくれるサイトが少なかったので。
こういうサイトが増えれば増えるほど色々な理解レベルに対応できるようになる(はず)。
rootってなに
計算ツールみたいなもん。素核宇宙実験系の解析が楽にできる。
やること
全体的に
ROOTをWindowsユーザーにもいい感じにコーディングできるようにする。
方法
①まずはWindows上でWindowsじゃない別のOSを走らせてくれる「VMware」を公式サイトからDL
www.vmware.com
これを実行してVMwareを入手。exeを実行して「VMware Workstation 16 Prayer」を起動してみる。
②一旦VMwareは置いておいて、「CentOS」の本体を公式サイトからDL
ftp-srv2.kddilabs.jp
別にこのバージョンでなくとも
・CentOS LINUXであること
・64bitのdvd.isoファイル(10GBくらいある)を選んでダウンロードすること
を満たしていればVMwareで起動することは簡単に可能。
③CentOSの本体を「安全な場所」に保管してVMwareからCentOSを起動
安全な場所とは
・「ダウンロード」フォルダではない
・OneDrive上にない
・間違って消さない場所
であればおk。



ユーザー設定はよしなに。(※このときの「root」は「管理者権限」のrootという意味なので間違えないこと)

起動できればおk。(初回は起動に20分くらいかかる)

次回
Cent OSの設定をする。
【備忘録】pythonで実験データを細かく解析するために、各種パラメータを辞書式で作る方法
はじめに
実験中検出器を様々なパラメータでデータを取ったはいいが、最終的にまとめるときには実験時のパラメータを代入する作業は辞書式で書かないとやってられなくなった。
某chが10個しかない検出器はごり押しで130runデータを普通のlistで書いていたが、某200chある検出器はそれでは厳しかったので今まで避けていた辞書式のlistで管理することを決意した。
学びの度に追記して記事の精度を上げたい。
使いどころ
- 手動で変えて取ったデータのパラメータを管理したいとき(HVの値、ビーム照射座標など)
- event loopによって1 eventごとにデータを見て解析をしたいとき
⇒データ解析時にdictを追加することで多段階解析も可能
本文
入力
hv_dict = {
'4418':{"1u":1900, "1d":1900, "2u":0, "2d":0}
'4434':{"1u":1900, "1d":2000, "2u-o":1900, "2d":2000},
'4445':{"1u":2100, "1d":2100, "2u-o":2100, "2d":2100}
} #定義
print(hv_dict["4418"])
print(hv_dict["4418"]["1u"])
hv_dict['4418']["2u-4"] = 2000 #追加
print(hv_dict["4418"])
出力
{'1u': 1900, '1d': 1900, '2u': 0, '2d': 0}
1900
{'1u': 1900, '1d': 1900, '2u-o': 1900, '2d': 0, '2u-4': 2000}
注釈
- 「:」の前部分がkeyで後ろ部分がvalueなので、前部分にパラメータの名前を書き、後ろ部分にパラメータの値を書く。
- 参照するときは外側のkeyから書く(2次元配列)
【備忘録】Pythonで動的に変数を取得する方法
状況
数独を解くプログラムの作成中に、先に変数名が決まっている状態で、数値代入をするかsympyのsymbol変数として扱うかを動的に決めたかったので調べた。
コマンド
exec()を使うと、()内のstringで打ち込んだコードを使用してくれる←日本語合っとるか??
書いたやつ
import sympy #A B C D E F G H I probrems = [[0, 0, 0, 9, 0, 3, 0, 0, 0], # a [2, 3, 0, 8, 7, 0, 0, 4, 0], # b [0, 0, 0, 0, 0, 0, 0, 0, 6], # c [5, 2, 0, 0, 8, 0, 0, 0, 0], # d [0, 0, 0, 2, 0, 0, 4, 0, 0], # e [4, 0, 0, 6, 0, 0, 1, 0, 2], # f [0, 0, 9, 0, 0, 0, 0, 0, 0], # g [7, 8, 3, 0, 9, 0, 0, 0, 0], # h [0, 0, 0, 0, 5, 0, 8, 0, 0]] # i values = [["Aa","Ba","Ca","Da","Ea","Fa","Ga","Ha","Ia"], ["Ab","Bb","Cb","Db","Eb","Fb","Gb","Hb","Ib"], ["Ac","Bc","Cc","Dc","Ec","Fc","Gc","Hc","Ic"], ["Ad","Bd","Cd","Dd","Ed","Fd","Gd","Hd","Id"], ["Ae","Be","Ce","De","Ee","Fe","Ge","He","Ie"], ["Af","Bf","Cf","Df","Ef","Ff","Gf","Hf","If"], ["Ag","Bg","Cg","Dg","Eg","Fg","Gg","Hg","Ig"], ["Ah","Bh","Ch","Dh","Eh","Fh","Gh","Hh","Ih"], ["Ai","Bi","Ci","Di","Ei","Fi","Gi","Hi","Ii"]] for hori in range(9): for vart in range(9): tmp = probrems[hori][vart] name = values[hori][vart] if tmp != 0: exec('{} = {}'.format(name,tmp)) if tmp == 0: exec('{} = sympy.Symbol("{}",positive=True)'.format(name,name))
出力
分かりにくいが、アルファベット部分はsympyのsymbolになってる。
[Aa, Ba, Ca, 9, Ea, 3, Ga, Ha, Ia] [2, 3, Cb, 8, 7, Fb, Gb, 4, Ib] [Ac, Bc, Cc, Dc, Ec, Fc, Gc, Hc, 6] [5, 2, Cd, Dd, 8, Fd, Gd, Hd, Id] [Ae, Be, Ce, 2, Ee, Fe, 4, He, Ie] [4, Bf, Cf, 6, Ef, Ff, 1, Hf, 2] [Ag, Bg, 9, Dg, Eg, Fg, Gg, Hg, Ig] [7, 8, 3, Dh, 9, Fh, Gh, Hh, Ih] [Ai, Bi, Ci, Di, 5, Fi, 8, Hi, Ii]
一口メモ
多分、for文で回しながらformatを使って可変量の変数を作り、処理しそう。
変数(listも同様)定義、処理、アウトプット全部exec()でやることになると思う。
formatがC++で言うsprintf()と同じと考えればわかりやすい(ハズ)。